Projecten
Bekijk alle projecten van de Hogeschool van Amsterdam. Zoek je een bepaald project? Gebruik dan de zoekfunctie bovenaan de pagina.
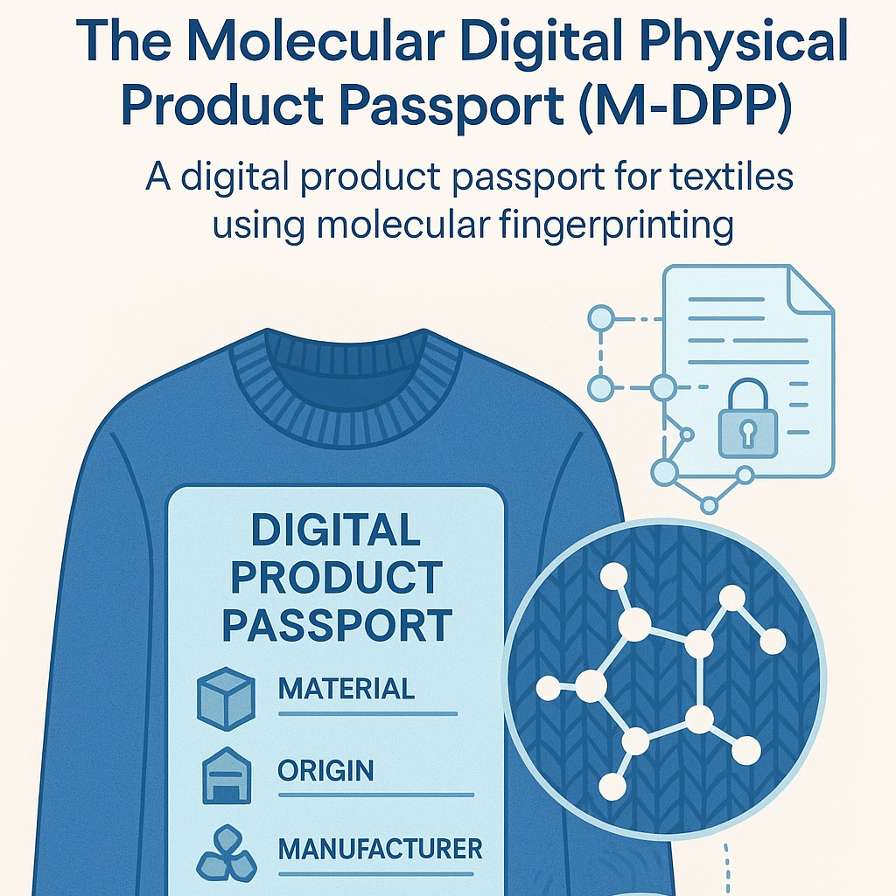
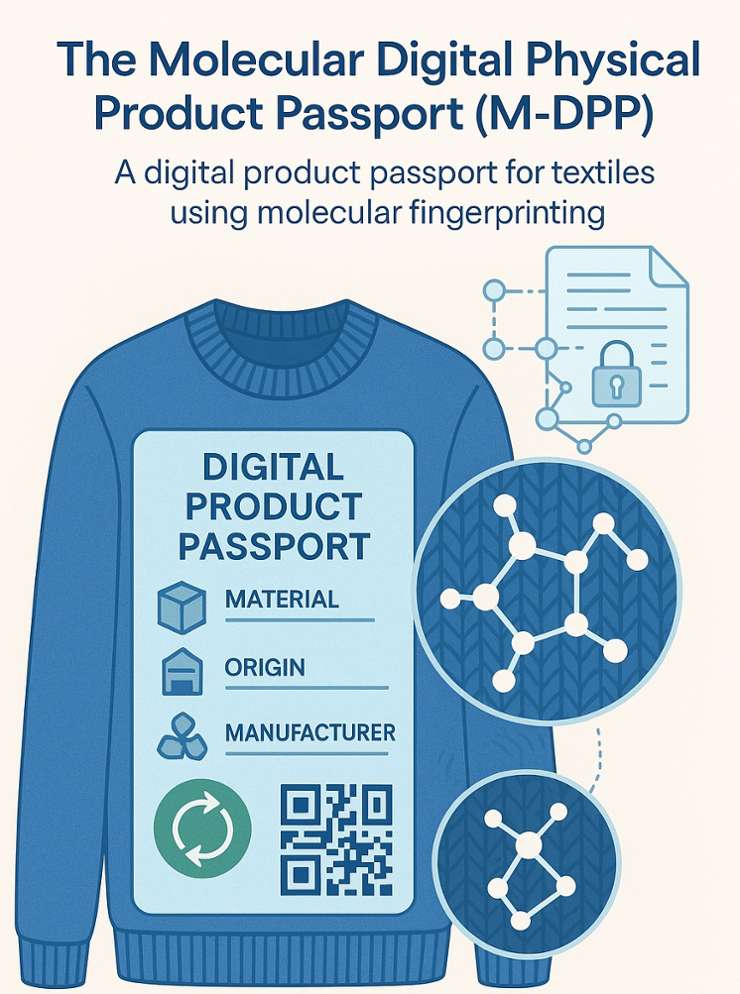
M-DPP - Digitale paspoorten voor traceerbare kleding
Reflectie-instrument voor verantwoorde AI-governance in publieke organisaties

RECOVER

Bruggen bouwen rond de basisschool - Hoe onderwijs en welzijn samenwerken om ouders en kinderen te ondersteunen

Het LESSEN Project

Creating the Desire for Change in Higher Education - Tools
eXtreme Citizen Science Hub Amsterdam

UrbanSWARM: nature-based solutions voor circulaire en toekomstbestendige steden

Beter productadvies in de winkel dankzij sociale robot met AI

Moralis Machina: In gesprek over generatieve AI met een kaartspel

Digital Tools for the Community Economy

ShoppingTomorrow 2025: Gezondere voedingskeuzes met in-store technologie

Gezondere voedingskeuzes in de supermarkt met Augmented Reality

You and AI: Designing AI-Equipped Jobs in Finance

Symfonie Foetsie - sociale veiligheid op de werkvloer

Burgerschapsonderwijs ontwikkelen en monitoren in po, go en vo